1. INTRODUCTION: WHY MT?
By a simple definition, machine translation (MT) is a technique that takes input in the form of a full sentence from a (source) language and generates its corresponding full sentence in another (target) language. It is considered as one of the key technologies that occupy a turnkey position in cross-lingual information exchange, inter-lingual communication, e-commerce, technology localisation, multilingual documentation, and many other realms.
The utility of MT technology was acknowledged by Hutchins (1986: 15) who argued that it can be used (a) by the professional world of scientists and technologists to translate various scientific and technical documents, (b) in the situations where there is paucity of human translators, (c) for the promotion of international co-operation through document transmission, (d) for the removal of language barriers by faster, easier, and cheaper transmission of technical, agricultural, medical information to the poor and developing countries, and (e) for military and commercial activities.
The utilities proposed by Hutchins are changed to a large extent. At present, globalization of information, expansion of multilingualism, demand for linguistic singularity, growth of literacy and readership, revolution in computer technology, cross-lingual language education, and various other factors have forced both the computer scientists and the linguists to join hands together for the development of a MT system that will be able to meet the requirement of the multimillion dollar market.
2. THE GOAL
Over the years MT technology has manifested remarkable growth both in use of techniques and in application. Yet, with huge amount of translatable texts in various languages, we are waiting for a MT system, which is robust in process, accurate in output, and applicable in all domains. Perhaps, we are too utopian in expectation. However, can we deny the fact that a MT system must have the potentials to add translation for new words and phrases, to include sophisticated functionalities such as adapting to new syntactic structures and writing styles, and to be customized for the users in order to succeed as a commercial product?
A MT system is not a simple ‘word to word’ replacement of the texts form one language to another. We ask for a kind of assurance that the produced text in the target language is 'grammatically correct' and 'conceptually acceptable.' The output should be nearest to the source text both in sense and content, if not identical. Moreover, information embedded in the source text must not be lost in the target text, nor some extra information, which was not originally present in the source text would be added in the target text.
3. PERFECT TRANSLATION IS NOT OUR IMMEDIATE GOAL
Since MT is not about creating perfect translation, outputs are either post-edited to an acceptable standard or used in unedited form as a source of rough information. It, however, aims for both linguistic and cognitive approximation, since its goal is to find ways and means to get as close as possible in as many cases as feasible. The goal is achievable through a long process of trial and error that involves evaluation of existing systems, identification of faults and limitations, refinement of systems, enrichment of past experience, and augmentation of linguistic knowledge. The path is full of thorns, yet tantalising because it dares to challenge the ability of both the MT software engineers and the computer linguists.
There are many hurdles on the path. They come not only from the fields of morphology, lexicology, syntax, and semantics, but also from the world of pragmatics, discourse, and cognition. Therefore, a MT system with the ability of a human translator is still an unrealised dream for which we have many miles to go. However, translation corpus seems to offer a promising direction for this task thanks to the progress made in terms of acquisition, storage, and processing of large amounts of language data by computer. Probably, a corpus-based approach can bring us nearer to our dream by enhancing the efficiency of a MT system.
4. LESSONS LEARNT FROM HISTORYFor the last half a century, works on MT are tried all over the world and almost all the major languages have been directly or indirectly involved, either as a source language or as a target language. But nowhere a complete success is achieved. This means till today there is not a system, which can automatically (without human intervention at its slightest proportion) produce translations in the target text that is well accepted by the target users without raising any question about its accuracy or validity. Although, people working in this area are able to put across sample texts in one language over the other a number of obstacles are still there.
Therefore, most researchers are now shifting from traditional rule-based system to corpus-based system. Results obtained from various methods [1] did not allow MT business to penetrate any more than a very marginal segment of global translation market.
5. MACHINE-AIDED-HUMAN TRANSLATION
Decades ago, Kay (1980) contemplated such failure and urged the community to shift from classical MT to machine-aided-human-translation (MAHT) system. While a few people felt Kay's proposal as more sensible, most of them preferred to stick to their own familiar system. The reluctance to give any serious consideration to MAHT was clearly an outcome of the impact of contemporary rule-based methods, although it was difficult to find out, within five decades of rule-based research, any single result, which is competent to challenge the outputs of MAHT system.
6. THE CORPUS BASED APPROACH
History has taught us that designing a MT system with a set of linguistic rules is not realistic at all. It is so because any sets of rules may not be enough to encompass the versatility of a natural language exhibited in the diverse discourse of life. This argument leads to the birth of an empirical corpus-based machine translation (CBMT) system, which combines both the example-based (Somers 1999)[2] and statistics-based machine translation (SBMT) approaches (Brown et al.1990)[3].
The very first result obtained within this new paradigm sets the path for the development of algorithms capable to align sentences of bilingual texts. This simple technique turns out to be of fundamental importance in MAHT, since it constitutes in itself a suitable foundation for many kinds of translation support tools. The CBMT system starts with the translations that are already produced by humans and seeks to discover their internal structures. This analysis-oriented perspective lends heavily to the development of translator's aids because in MAHT the machine is not expected to 'produce' translations, but rather to 'understand' enough about them to become helpful.
7. USING BILINGUAL COPORA FOR MT
The idea of using bilingual corpora in MT is not a new thing. It dates back to the early days of MT, but it was not used in practice until 1984 (Kay 93). The CBMT system is based on the information acquired from analysis of bilingual corpora. Since these corpora are very rich with information, they provide situational equivalency information on the possibilities of a language system when in contact with a different language system. Thus, CBMT system combines both EBMT and SBMT approaches with a mutual interactive interface between the two. It is based on the variety of information developed from the analysis of language database of words, phrases, sentences and paragraphs both in the source and in target language, as well as on statistical system that uses various probability calculations to identify the translation equivalents between the texts included in corpora.
The basic method is grounded on the conviction that there are no pre-established solutions to translation, but most possible solutions are found in the texts already translated by the professionals. In other words, a large portion of a translator's competence is encoded in the language equivalencies found in already translated texts. Recent success in this approach (Teubert 2002) in restricted domains leads us to argue that we need both linguistic and extra-linguistic knowledge to achieve similar success in general domains. Although it is too early to make any prediction about its success in all domains, we can argue that a method developed with proper utilisation of information acquired from well designed translation corpora will be much more robust and useful both in restricted and general domains (Su and Chang 1992).
8. ISSUES RELATED WITH CORPUS BASED SYSTEM
The CBMT system has made considerable progress through corpus research. Here translation corpora are developed and used to yield important insights. Generally, these corpora represent a large collection of naturally occurring language samples accumulated from texts reflecting the needs of the end-users. This is important for the people, who want to select a system that translates specific text of their need. In such system, use of translation corpora is compulsory, since they serve different purposes with the supply of linguistic and non-linguistic information of various types. In the following sections issues of the CBMT system are discussed with examples obtained from the Bangla corpus (Dash and Chaudhuri 2000).
9. GENERATION OF TRANSLATION CORPORA
Translation corpora consist of original texts and their translations into another language. These corpora keep meaning and function constant across the languages to offer an ideal basis for comparing realisation of particular meanings in different languages under identical conditions. They also make it possible to discover cross-linguistic variants, i.e. alternative renderings of a particular meaning in the target language. Thus, translation corpora provide a fruitful resource of cross-linguistic data (Altenberg and Aijmer 2000: 17).
Construction of translation corpora is a complicated task that requires constant careful guidance of experienced corpus linguists. It should be made in such a way that it combines the advantages of both comparable and parallel corpora. Text samples are matched as far as possible in terms of text type, subject matter, purpose, and register. The possible structure of translation corpora within two languages is designed in the following way (Fig. 1) keeping in mind the aim of the task and the components to be integrated within corpora.
Fig. 1: Proposed structure of translation corpora
(Partly adapted from Altenberg and Aijmer 2000: 17).
The diagram shows that translation corpora are designed in such a way that they can be further used as comparable corpora (vertical arrow joining left-hand circles) and bi-directional translation corpora (horizontal arrows), for comparing original and translated texts in the same language (diagonal arrows), and for comparing translated texts in the two languages (vertical arrow joining right-hand circles). Selection of text samples for such corpora are generally guided by the following principles:
- Language used in written texts only is included in translation corpora. There is no chance for the texts obtained from spoken discourse to be included in it, since present MT research targets written texts only.
- Included texts reflect on the contemporary language use although texts of old ages have relevance in translation of historical texts.
- Texts are not restricted to any specific regional or language variety. They include a wide range of samples obtained from various domains of language use.
- Texts from both languages are maximally comparable. They match in genre (e.g. news), type (e.g. political), content (e.g. election), and form (e.g. report). They also match in terms of purpose, type of user, subject matter, and register.
- Texts included in translation corpora contain large and coherent extracts taken from the beginning to the end of a natural breaking point (chapter, section, etc.).
Generation of translation corpora in Indian languages is a real problem. It involves acquisition of translated texts, conversion of general corpus into translation corpus, formatting the corpus into machine-useable form, alignment of corpora, etc. After the procurement of translation corpora and defining correspondences within units, they are submitted to the task of 'item search' - statistical technique, which reduces problems presented by other levels of analysis. Criticism against the CBMT system points towards the paucity of corpora designed for this purpose, since CBMT system requires translation corpora as well as detailed analysis of these by human experts (Elliott 2002).
10. DEVELOPMENT OF CORPORA IN INDIAN LANGUAGES
We, therefore, argue for the development of translation corpora in Indian languages not only to meet the research requirements but also to evaluate the efficiency of the existing MT systems. Probably, information of how corpora are used in translation from other languages to English can benefit us, since it will help us to discover the patterns of the languages linked to the specific source language (Baker 1993). Moreover, this will provide much-required insights into the relationships between the two languages considered for translation.
11. ALIGNMENT OF TRANSLATION CORPORA
Aligning translation corpora makes each ‘translation unit’ of the source text to correspond to an equivalent unit of the target text. It not only covers shorter sequences like words, phrases, and sentences, but also larger sequences such as paragraphs and chapters (Simard et al. 2000).
Selection of translation units depends on the point of view chosen for linguistic analysis and on the type of corpus used as database. If translated corpus demands high-level faithfulness to the original, as in the case of legal and technical corpora, the point of departure will be a close alignment of two corpora, considering sentences or even words - the basic unit.
On the other hand, if the corpus is an adaptation, rather than literal translation of the original, attempt will be made to align larger units such as paragraphs or even chapters. Alignment task is thus refined based on the type of corpus where the linearity and faithfulness of human translation can help to a great extent. This is particularly true to the technical corpora. Literary corpora also lend themselves to reliable alignment of units below the sentence level if the types of equivalency observed in the corpora are previously formalised (Chen and Chen 1995).
12. THE INITIAL STAGE
At the initial stage, correspondence between the contents of units considered and their mutual relationships allow the corpora to be aligned. However, such ‘free’ translations may present a serious processing problem due to their missing sequences, changes in word order, modification of content, etc. All these features are common in everyday translation practice, but their frequency varies according to the field of the corpus. It leads us to consider that an aligned corpus is not a set of equivalent sequences, but a set of ‘corresponding text databases’. At any level (i.e. text, paragraph, sentence, word, etc.) it is considered as a simple lexical database with 'parallel units'. The objective is not to show structural equivalencies between the two languages but to search the target text unit that is closest to the source text unit. To do so, the starting point is the preliminary alignment of words with the help of a bilingual dictionary. Such rough alignment yields satisfactory results at sentence level (Kay and Röscheisen 1993) when combined with statistical method (Brown and Alii 1990, Brown, Lai, and Mercer 1991) with minimum formalisation of major syntactic phenomena (Brown, and Alii 1993).
13. SENTENCE ALIGNMENT
Sentence alignment is another important part of the CBMT system. It aims to show matching down to the sentence level. For this, a week translation model will do (Simard, Foster, and Isabelle 1992) since this is required at the initial stage of translation analysis (discussed below). Research is currently underway to develop analysers capable to account for finer translation correspondences between phrases, words, and morphemes.
Recent techniques (Oakes and McEnery 2000) have opened the way to a whole new family of translation support tools, including translation memory applications, translation checkers, translation dictation systems, etc. The main advantage of this method is the use of translation memory that integrates data found in text databases. The task is further simplified by the use of reference corpora of specialised fields (e.g. legal, computer science, medical, etc.). Thus, messages are 'machine' translated essentially by using a customised dictionary and a translation memory created by human translators during the training phases.
14. USE OF STATISTICAL METHODS
Another interesting aspect of the proposed method is the use of some statistical techniques for searching the databases. The statistical searching algorithms use the key words to retrieve equivalent phrase segments in the two different texts. Once they are found, they are formalised by human translators as models before being stored in the translation memory. This process is recommended for ‘automatizing’ the training part and not for validation. Here lies the difference between the automatic machine translation (AMT) and machine assisted human translations (MAHT) supported by the parallel texts of translation corpora.
15. TRANSLATION ANALYSIS
Among the MT researchers, the central point of debate lies in the complexity of translation analysis. It is argued that unless a large number of linguistic phenomena occurring in natural texts are analysed and represented, a quality translation system is probably unattainable. It is also argued that problems like ambiguity and constituent mapping can only be dissolved with the help of knowledge obtained from translation corpus and stored in lexicon and grammar of each language. This requires rigorous translation analysis that aims to make explicit all translation correspondences that link segments of the source text with those of the translations.
Besides the task stated above, translation analysis has various other applications both in language technology and education, as mentioned below.
· It is used to structure pre-existing translations so that they become reusable in production of new translations. For instance, the CWARC's TransSearch system (Isabelle et al. 1993) is a bilingual concordancing tool that allows translators to search special-purpose databases for ready-made solutions to specific translation problems.
· It is applied to draft translations for detecting certain kinds of translation errors. Once we reconstruct the translation correspondences between the source and the target texts, we can verify if these correspondences have any constraints. For example, it is possible to say that the translation is complete in the sense that all large chunks (e.g. paragraphs, sentences, etc.) of the source text are translated.
· It is used to verify if translation is free from any kind of interference errors caused by 'deceptive cognates' (e.g. Bangla sandesh and Hindi sandesh are not acceptable translational equivalents. The same is true to Bangla bou and Oriya bou, English pun and Bangla pAn or English bill and Bangla bil).
16. LINGUISTIC TASKS ON TRANSLATION CORPORA
Translation corpora, after compilation, pass through the stages of automatic alignment and analysis before they are exposed to various levels of linguistic analysis and interpretation. Linguistic analysis, in general, serves as a foundation for the purpose of formalisation of translation equivalencies. In general, it involves:
- Morphological analysis to identify words and morphemes in translation corpora,
- Syntactic analysis to identify syntagms and their functions in respective corpus,
- Morphosyntactic analysis to ensure both accurate and effective analysis, and
- Semantic analysis to identify meanings of the units and any ambiguities involved therein.
For linguistic analysis, the best way is to use 'superficial' morphosyntactic descriptive method (i.e. part-of-speech tagging and shallow parsing) along with a 'statistical' method for probability measurement. The analyser is supported by a grammar acquired from the previously processed corpora, since such corpora usually transcend its application in subsequent stages. While the main objective is create translation memories, other applications may also be considered, such as drawing up bilingual terminological lists and extracting examples for the purpose of computer-assisted language teaching. Once annotated, corpora are used as the basis for the enhancement of electronic dictionaries or to create grammar books.
In an ideal system, the POS tagging is performed automatically by comparing texts of the corpora following a probabilistic procedure. Although, in this way, sometimes an adjective is translated as a noun or vice-versa, the categories given by standard dictionary help to resolve such situations. In this case, standard grammatical categories will have a strong impact on the quality of tagging, since a system with fewer categories have much greater success rate than a system with an exhaustive list of categories (Chanod and Tapanainen 1995).
17. FORMATION OF BILINGUAL DICTIONARY
Bilingual dictionary is a useful tool for CBMT system, the lack of which is one of the bottlenecks in the present MT research in India. Usually, standard dictionaries cannot compensate this, since they do not contain enough information about the lexical sub-categorisation, selection restriction, and domains of application. It is noted that lexical sub-categorisation information to be included in bilingual dictionary is extracted semi-automatically from a tagged corpus using statistical methods (Brown 1999). Also, dictionaries produced from untagged corpora are equally useful for this purpose. For the formation of bilingual dictionary, generally statistical methods are applied to extract (a) large comparable syntactic blocks (e.g. clauses, phrases, etc.) from parsed corpora, (b) subcategorised constituents (e.g. subject, object, predicate, etc.) from tagged corpora, and (c) frequently occurring set phrase and idioms from parsed corpora.
18. APPLICATION TO INDIAN LANGUAGES
Formation of bilingual dictionary is best possible within the two typologically or genealogically related languages (e.g. Hindi-Urdu, Bangla-Oriya, etc.) since they share many features (both linguistic and non-linguistic) in common. Moreover, there is large chunk of regular vocabulary, which is similar to each other not only in phonetic and orthographic representations but also in sense, content (meaning), and implication. For instance, consider the following sample word list similar to the two cognate languages: Bangla and Oriya.
Lexicon
Bangla words = Oriya words
Relational term
bAbA = bapA, mA = mA, mAsi = mAusi, didi = apA, dAdA = bhAinA, bhAi = bhAi, chele = pilA, meye = jhiya, putra = po, kanyA = jhi
Pronoun
Ami = mui, tumi = tume, Apni = Apana, tui = tu
Noun
lok = loka, ghar = ghara, hAt = hata, mAthA = munDa, pukur = pukhuri, kalA = kadali
Adjective
bhAla = bhala, kAla = kalA, satya = satya, mithyA = michA.
Verb
yAchhi = yAuchi, khAba = khAibA, Asche = asuchi
Postposition
mAjhe = majhire, tale = talare, pAshe = pAkhre
Indeclinable
ebang = madhya, kintu=kintu
Table 1: Similarity in vocabulary between Bangla and Oriya
Definitely, we cannot expect a hundred percent congruence at morphological, lexical, syntactic, semantic and conceptual level within the two related languages. Therefore, with all the knowledge of linguistic theories and corpora, a Core Grammar is the best solution, which is yet to be developed among the related Indian languages. However, with present availability of information from systematic analysis of corpora in Indian languages, we can achieve marginal success in the area of dictionary generation.
19. EXTRACTION OF TRANSLATION EQUIVALENTS
Translation corpora allow us to start from a form (or set of forms) expressing certain meaning in one language and to search out their equivalent(s) in another language. Normally, theyreveal a large range of equivalents, a potential source for alternative verification. The factors that determine the choice of appropriate equivalents are determined on the basis of recurrent patterns of use. If necessary, these equivalent forms revealed in each language are verified with the original texts or by the texts stored in large monolingual corpora representing the two languages.
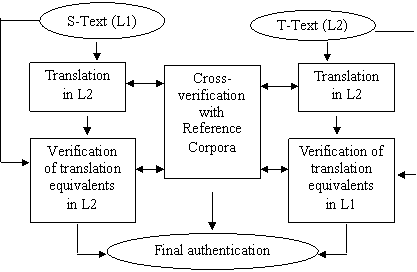
The process of extracting equivalent units from translation corpora and their subsequent verification with monolingual corpora is graphically presented below (Fig. 2). Extraction of translation equivalent units from translation corpora will enable MT designers and others to build on the resources, since translation corpora will help them to find suitable translation equivalents. Thus, translation corpora will enable them to:
· retrieve translation equivalent units including words, idioms, compounds, collocations, and phrases,
· learn how corpora help to produce translated texts that display 'naturalness' of the target language,
· create new translation databases, which enable users to translate correctly into a foreign language of which they have only limited command, and
· generate new terminology databank, since a large proportion of terminological material in new texts is neither standardised nor recorded in 'term banks'.
For finding equivalent units, various searching methods are used to trace comparable units of meaning in texts, which are often larger and complex than simple words. Implemented into a translation platform, these facilitate translations with more than customary translation memories. Moreover, we can propose various suggestions to integrate corpus findings with bilingual dictionary, multilingual term bank, and the database of translation equivalents.
Fig. 2: Verification of translation equivalents for authentication
However, even in closely related languages, translation equivalents seldom mean the same thing in all contexts or are used in the same type of syntactic environment. Moreover, their connotations as well as their degree of formality may differ depending on the language. Even when a word of the target language, which is used as the translation equivalent of the lemma in the source language, is not always the lemma in the target language. Simple, two-way translation may be possible with the names of animals or tools and with some scientific terms, but rarely with more ordinary language (Landau 2001: 319). This signifies that for ordinary language a CBMT system will face many problems, which will require a high degree of linguistic sophistication. Where there are fewer problems, as in the case of scientific and technical language, the CBMT system will produce the best possible outputs.
20. GENERATION OF TERMINOLOGY DATABANK
Coinage of appropriate technical and scientific terms for machine translation requires thoughtful introspective analysis of terminologists. Here the basic function is to find out an appropriate term that will be equivalent or nearly equivalent in sense to represent a ‘foreign’ idea, item or concept in the target language. While doing this, the terminologists need to keep the following factors in mind:
· The newly coined term should be grammatically regular in the target language,
· It should contain the idea of the scientific event, item, concept for which it is made,
· It should have a compact structure to be used easily by the common users,
· It should have the feature of generativity by which more forms can be generated by using exiting word formation repertoire available in the target language, and
· It should be easy to articulate and good to listen.
21. CHOICE OF APPROPRIATE TERMS
Translation corpora have important role to play in the choice of appropriate terms from the score of multiple terms coined by different persons to represent an idea, item or concept. It is noted that recurrent practice of formation of new technical terms often goes to such an extent that the MT designers are at loss to decide which one to select over the other.
Debate also arises whether one should generate a new term or simply accept the source language terms, which are nativized in the target language by regular use and reference. At certain times, some technical terms become nativized to such an extent that it becomes impossible to trace their actual origin. In such cases the MT designers do not have much problem, since these terms have achieved the quality of acceptability among the users of the target language. For instance, Bengali users have little difficulty in understanding terms like computer, mobile, calculator, telephone, tram, bus, cycle, taxi, rickshaw, train, machine, pen, pencil, pant, road, station, platform, etc. because these are already accepted in the language along with respective items. Their frequent use has made them the part of the Bangla vocabulary. Therefore, there is no need for replacement of these terms at the time of translation.
But, in case of the selection of appropriate terms from the native language for an idea or concept newly borrowed from outside, the translation corpora are able supply terminologists with necessary databases to draw sensible conclusions.
22. CONTRIBUTION OF COPORA TO INDIAN LANGUAGES
Here, corpora contribute in two important ways. First, they help terminologists to assemble all the terms entered into the language along with their date and field of entry. Second, they provide all possible native coinages of particular terms along with their respective domains and frequency of use. These factors help the terminologists to determine over the issue of relative acceptance or rejection of the terms in translation. To understand how corpora contribute in the choice of appropriate technical terms, let us examine some instances taken from the Bangla corpus.
The Bangla paribhAsA (technical term) for the English word urgent is coined as Atyaik by Tagore (1909/1995: 475). But in the corpus this term is never used while a common and easier form jaruri is noted to have highest occurrence across all text types. The coinage of Tagore is rejected because it fails to fulfil the conditions mentioned above. Similarly, for the English medical term nyctalopio, the corpus cites a regular form rAtkAnA, which is far more appropriate than rAtri-andhatva proposed by Ghosh (1993) and AndhArkAnA proposed by Dev (1999). Even from the point of occurrence, rAtkAnA is more frequent than other two terms. Thus, considering use and linguistic relevance, we accept or reject terms in terminology databank.
23. FINDING LEXICAL SELECTION RESTRICTION IN INDIAN LANGUAGES
A typical example of lexical selection restriction is the use of verb depending on the status of the agent (actor). In Bangla, for example, the use of verb referring the 'act of dying' is highly restricted depending on the honour adorned by a person. Here, a divine man tIrodhAn karen, a great man paralok gaman karen, an honourable man dehatyAg karen, a common man mArA yAy, a hero mrityu baran karen, a buffoon paTal tole, a fortunate gangAlAbh karen, a noble man panchabhute bilIn han, an ignoble man tnese yAy, an old friend svargArohan karen, but an enemy yamer bARi yAy, etc. Such cases must be taken care of to solve the problem of lexical selection often carefully handled in human translation but ignored in machine translation. The best way to deal with this problem is to list them separately in a machine-readable dictionary (MRD) to be used in the task. If translation corpora are available, one can extract such information to use in future translations.
Selection of appropriate terms is further complicated if we take into account the context of use of words across the fields of discourse. For instance, consider the English word delivery. What it means in the field of childbirth is not similar in the context of classroom lecture, postal distribution of goods, and speech made at a mass rally. Therefore, considering the discourse of use of the terms, the terminologists have to coinage the appropriate term in the target text. While, in the field of childbirth the most appropriate term in the target text is prasab karA, in case of classroom teaching it is paRAno, in postal distribution it is pounche deoyA, and in mass rally it is baktritA deyoA. Thus, evidences obtained form the corpus will legitimatize the utility and acceptance of the terms.
24. SELECTION OF APPROPRIATE PHRASES
Selection of appropriate phrases and idioms is another important part, which asks for careful handling of the translation corpora. The best solution is the generation a bilingual dictionary of these items and subsequent storage in a MRD for appropriate contextual use. Generation of such lists and their use will enhance the quality of machine translation, since such bilingual databases intend to encompass the figurative senses expressed both in the source and the target texts for stylistic representation and better comprehension.
25. DISSOLVING LEXICAL AMBIGUITY
A typical human communication involves transfer of mental representation of speaker to listener by using natural language as a vehicle. Sometimes this transfer is not free from ambiguities, which may arise due to inadequacy of inherent meaning associated with the lexicon and structure of sentences used in communication. A speaker may use more than one word or sentence to clarify the same concept, which is further compounded when the language of the speaker is different from that of the listener. Since a translation system is usually built by the perception of the speaker's mental representation, it is limited by the words and sentences used by the speaker. To overcome this, the translator has to map the source lexicon to the equivalent target lexicon, which is most appropriate to a given context. In some cases, the target language may not posses an equivalent item that can represent the original flavour of the source language. In such cases, the translator has to resort to a cluster of lexicons (e.g. multiword units like phrase or clause) or explanatory addendum to overcome the problem.
For the ambiguous lexical items we have to find ways to locate their contexts of use to analyse their contextual profiles for disambiguation. However, recent corpus-based analysis (Ravin and Leacock 2000, Cuyckens and Zawada 2001) shows that lexical ambiguity is caused because words allow more than one reading.
Words differ in terms of their sub-categorisation and selectional features, syntactic and semantic properties as all as for features such as tense, modality, case, number, possibility of idiomatic readings and so on (Sinclair 1991:104). For instance, Bangla words like mAthA, kathA, path, khAoyA, karA, kATA, kAncA, pAkA, bhAlo, etc. are associated with multiple readings due to variation of their context of use that trigger both lexical and figurative senses.
26. ARGUMENTS AMONG RESEARCHERS
Among the MT researchers, it is argued that to overcome the problem of lexical ambiguity, a large number ambiguous forms widely occurring in natural texts should be analysed and overtly represented to achieve high quality translation. Almost all the ambiguous forms have to be analysed with the help of abundant knowledge obtained from translation corpora and stored in dictionary. On the contrary, some others have argued that such linguistic information acquisition is neither realistic nor feasible (Grishman and Kosaka 1992).
It must be kept in mind that translation process does not necessarily require full understanding of the text. Many ambiguities may be preserved during translation … and thus should not be presented to the user (human translator) for resolution (Ari, Rimon, and Berry 1988).
For instance, the word head can be translated into Bangla as mAthA no matter in which of the numerous senses of head it is used in the source language. For this, it is better to use a more direct source-target language substitution approach in place of the meaning analysis involved with a particular ambiguous lexical unit.
At certain contexts, it is possible and necessary to ignore ambiguities, with the hope that same ambiguities will carry over in translation. This is particularly true to the system that deals with only a pair of closely related languages within a restricted domain. Analysis of ambiguities is meant to produce a non-ambiguous representation in target language hence cannot be ignored in case of general domain-independent translation (Isabelle and Bourbeau 1985: 21).
27. GRAMMATICAL MAPPING
The type of transformation referred to here is called 'grammatical mapping.' Here, a word of the source text is 'mapped' onto another word in the target text to obtain right translation. There are various kinds of mapping, the most common of which is the one that maps one verb to another (Fig.3).
Input
All
his
efforts
ended
in
smoke
(a)
(b)
(c)
(d)
(e)
(f)
Literal output
samasta
tAr
chesTA
sesh hala
-te
dhonyA
(1)
(2)
(3)
(4)
(5)
(6)
Actual output
tAr
samata
chesTA
byArtha hala
(2)
(1)
(3)
(4-5-6)
(2)
(1)
(3)
(7)
Fig.3: Example of grammatical mapping from English to Bangla
Lexical information:
a = 1 : (word to word mapping)
b = 2 : (word to word mapping)
c = 3 : (word to word mapping)
d = 4 : (group of words for single word)
e = 5 : (use of case marker for preposition)
f = 6 : (word to word mapping)
Pragmatic information:
Source language: (d-e-f-): an idiomatic expression
Target language: (7 [<4-5-6]): similar translation equivalent
Sentential information:
Sequence in source language: (a + b + c + [d + e + f])
Sequence in target language: (2 + 1 + 3 + 7 [<4+5+6])
The CBMT system is provided with the information that the phrase ended in smoke in the source language is to be translated as byArtha hala in the target language when the phrase is used in an idiomatic sense. Only then we get the output: tAr samata chesTA byArtha hala.
Such mapping from one structure to another is especially helpful for producing translations, which are accepted as ‘normal’ constructions in the target language. Also, analysing the sentence structures of the previously made translation corpora, it is possible to map the sequences of word order (at linear level) between the source and the target language.
This will produce valuable information about the structures of the NPs, VPs, PPs, and other sentential properties used in both the languages. It will also highlight the grammatical mapping underlying the surface structures of the sentences to know the kind of lexical dependency works beneath the surface constructions. For instance, the prepositional forms (e.g. at, up, by, in, of, with, etc.) used in English will be mapped either as postposition or case markers in Bangla translation. For example, let us consider the followings (Table 2):
English
Bangla
in hands
hAte (< hAt[NN] + -e[Loc_Case]),
with person
loker (< lok[NN] + -er[Gen_Case] ) + sange[Post-p])
by mistake
bhulbashata (< bhul[NN] + bashata [ADV])
in house
ghare (<ghar [NN] + -e [Loc_Case])
in house
gharer madhye (< ghar[NN] + er [Gen_Case] + madhye [Post-p])
at night
rAte (rAt[NN] + -e [Loc_Case])
Table 2: Mapping of Bangla postpositions with English prepositions
It will also provide information about their position in respect to the content word with which these functional words are attached to.
28. THE IMPORTANCE OF GRAMMATICAL MAPPING
Therefore, grammatical mapping is must for MT. Analysis of exiting translation corpora will optimise mapping of equivalent constructions in order to obtain the best possible translation outputs. The basic aim is to associate equivalent constructions (e.g. multiword units, idioms, phrases, clauses, and larger syntactic structures) with typical formal structures at the time of corpus analysis, where basic purpose is to allow the pairing mechanism to be broken down into three parts:
· Identification of potentially associatable units in the two corpora;
· Formalisation of the structure of associatable units using morpho-syntactic tags;
· Determination of the probability of proposed structures by comparing them to the effective data of the translation corpora.
Dividing the process into phases, relatively simple translation models are produced, so as to determine the units likely to correlate the theoretical analysis with actual translations observed in corpora. One of the possible ways to make it easier is to develop analysis methods based on the data stored in training corpora. However, such methods, based on model training, depend on the amount of information available a priori, i.e. on syntactic rules previously developed by human experts.
It should be, however, emphasised that it is not necessary to analyse all the sentences used in translation corpora to find the rules of the languages. A set of types rather than the full set of tokens will serve the initial purpose because:
· There are units, which are identical in form and component. That means, a single unit (say, a NP) may correspond structurally to some other NPs within the same corpus. This is true to both the source and the target language.
· Sequence and interrelationships between the units in the target text may be same with those in the source text if the translation corpora are developed from the two closely related languages (e.g. Bangla and Oriya).
· There are fixed reference points, which can easily mark out two texts and allow the identification of translation units. This is the case for numbers, dates, proper nouns, titles and layout (e.g. division of paragraph, section, etc.).
29. GRAMMATICAL MATCHING
Based on the analysis of grammatical equivalencies obtained from the translation corpora, the following types of grammatical matching will be found:
· Examples of strong matching where there the number of words, their order, and their meaning are the same.
· Examples of approximate matching where the number of words and their meanings are same, but not the order in which they appear.
· Examples of weak matching where the word order and the number of words are different, but their dictionary meanings are the same.
In case of English to Bangla translation, most of the grammatical mapping will be weak, since they belong to two different typological classes (English is SVO type whereas Bangla is SOV type). In such situation, alignment of corpus of the languages must not rely only on the syntactic structures of respective texts, but must have the provision for semantic anchor points. As long as 50% words in a sentence of source text semantically correspond to at least 50% words in a sentence of target text, the sentences may be assumed to have an equivalency or translational relationship.
The reliability of such a system is guaranteed by an intermediate alignment stage of text at paragraph or possibly at sentence level. Thus, if five words appear in sentence S1 of the text T1 and the search of corpus makes five words of equivalent meanings appear in sentence S2 of the text T2, the two sentence units are assumed to have translational relationship. To ensure greater reliability in searching operation, a ‘regressive’ alignment technique is used on the translation that proceeds from the largest translation units (i.e. chapters and paragraphs) to the smallest ones (i.e. sentences followed by phrase and words). Moreover, by use of regressive alignment technique (focusing on smaller to smallest units) the following hypotheses are verified:
· Any two chapters are considered to have translational relationships if at least five paragraphs of each chapter correspond to each other.
· Any two paragraphs are considered to have translational relationship if at least five sentences of each paragraph correspond to each other.
· Any two sentences are considered to have translational relationship if at least five words of each sentence correspond to each other.
· Any two are considered to words have translational relationship if at least one of their meanings correspond to each other.
30. THE SYSTEM MODULE
Methodically, combination of linguistic approach with statistical approach makes it possible to fine-tune the alignment of texts to enhance processing of the translation corpora. Besides, it requires identification and formalisation of translation units as well as utilisation of bilingual dictionary. Therefore, there is no need for exhaustive morphosyntactic tagging of each translation corpus. Machine will find equivalencies by comparing the two corpora that have translational relationship. However, to ensure quality performance of the system, the following aspects must be taken care of.
- The standard of the translation corpora must be high. The data (aligned bilingual texts) may pose a problem if the quality of corpus is poor or if it has not been subjected to strict control by the human experts.
- The quality and size of bilingual dictionary must be enhanced. The dictionary is the basic source in terms of grammatical information provided. Therefore, it must include unknown words found in the bilingual corpora.
- The accuracy of the system and the quality of translation will depend heavily on the volume of training data available for the purpose as well as on the accuracy of corpus synchronisation.
With above resources, a CBMT system is expected to be robust in output. However, a long training phase on large amount of different text data is an essential imperative. Once this stage is completed, information stored in the translation memory will be reactivated to yield all kinds of translation solutions that were previously the exclusive domain of human experts. To achieve complete success, a dose of artificial intelligence will probably have to be integrated into the system thus designed.
The groundwork presented here is a proposition for developing useful CBMT system that will allow us to translate all types of text from one language to another. The use of training corpora may advance MT research despite the fact that corpus for Indian languages present a few practical problems.
31. CONCLUSION
Machine translation is an applied field and it is quite appropriate that the impetus for progress have come in a large part from the extra-linguistic sources. It is a specialised domain, which unlike most others, is an worthy test bed for linguistic theories (of syntax, semantics, pragmatics, and discourse), computational-linguistic methods (e.g. algorithms for parsing, semantic and pragmatic interpretation and text generation), descriptive linguistics (lexicon and grammars for particular languages), modelling human reasoning resources (i.e. knowledge representation and manipulation), and translation studies. It is an ideal field for comprehensive evaluation of computational theories of language as well as for the development and testing of a wider range of specific language phenomena.
From the Indian perspective, translation corpora are primary prerequisite, which could be fruitfully used for developing CBMT systems. Translation corpora will be used to perform a two-way role: as input for developing CBMT systems as well as test-beds for evaluating the existing systems. Thus, translation corpora will make significant contribution to the capability of our systems. Recent success in corpus-based method has directed researchers to adopt this method to supplement traditional rule-based approaches. Information obtained from analysis of translation corpora has minimised the distance between the source and the target language.
This has been the outcome in some domain specific CBMT systems within the controlled languages where all types syntactic, lexical and terminological ambiguities are ignored (Teubert 2000: 10). Such a system usually narrows down the gulf of mutual intelligibility to enhance translatability between the two languages used in translation corpora. If we are to develop an efficient MT system for the Indian languages, we probably cannot ignore the value of translation corpora.
NOTES
[1] From the beginning of research in machine translation, various approaches and techniques (e.g. Rule-based approach, Knowledge-based approach, Transfer-based approach, Dialogue-based approach, Statistics-based approach, Example-based approach, Hybrid approach, Interlingual approach, Task-based approach, etc.) are used. Due to a different goal of the present paper these approaches are not discussed here. For details see Hutchins (1986) and Elliott (2002).
[2] Example-based Machine Translation approach aims at using past (i.e. mostly man-made) examples of translated texts both for new translations as well as for fine-tuning the old outputs.
[3] Statistics-based Machine Translation opts to rely on statistical probability measures obtained from empirical corpus database to translate texts as well as to provide translation equivalents for the target language.
REFERENCES
Altenberg, B. and K. Aijmer (2000) “The English-Swedish Parallel Corpus: A resource for contrastive research and translation studies”. In Mair, C. and M. Hundt (Eds.) Corpus Linguistics and Linguistics Theory. Pp. 15-33. Amsterdam-Atlanta, GA: Rodopi.
Ari, B., D.M. Rimon, and D. Berry (1988) “Translational ambiguity rephrased”. In Proceedings of the 2nd International Conference on Theoretical and Methodological Issues in Machine Translation. Pittsburgh. Pp. 1-11.
Baker, M. (1993) “Corpus linguistics and translation studies: implications and applications”. In Baker, M., F. Gill, and E. Tognini-Bonelli (Eds.) Text and Technology: In honour of John Sinclair. Pp. 233-250. Philadelphia: John Benjamins.
Brown, P. and M. Alii (1990) “A Statistical approach to machine translation”. Computational Linguistics. 16 (2): 79-85.
Brown, P. and M. Alii (1993) “The mathematics of statistical machine translation: parameter estimation”. Computational Linguistics. 19(2): 145-152.
Brown, P., J. Cocke, S.D. Pietra, F. Jelinek, R.L. Mercer, and P.S. Roosin (1990) “A statistical approach to language translation”. Computational Linguistics. 16(1): 79-85.
Brown, P., J. Lai, and R. Mercer (1991) “Aligning sentences in parallel corpora”. In Proceedings of the 29th Meeting of ACL.
Brown, R.D. (1999) “Adding linguistic knowledge to a lexical example-based translation system”. In Proceedings of the MTI-9. Montreal. Pp. 22-32.
Chanod, J.P. and P. Tapanainen (1995) “Creating a tagset, lexicon and guesser for a
French tagger”. In Proceedings of the EACL SGDAT Workshop on Form Texts to Tags Issues in Multilingual Languages Analysis, Dublin. Pp. 58-64.Chen, K.H and H.H. Chen (1995) “Aligning bilingual corpora especially for language pairs from different families”. Informations Sciences Applications. 4(2): 57-81.
Cuyckens, H. and B. Zawada (Eds.) (2001) Polysemy in Cognitive Linguistics. Amsterdam/ Philadelphia: John Benjamins.
Dash, N.S. (2003) “Corpus linguistics in India: present scenario and future direction”. Indian Linguistics. 64(1-2): 85-113.
Dash, N.S. and B.B. Chaudhuri (2000) “The process of designing a multidisciplinary monolingual sample corpus.” International Journal of Corpus Linguistics. 5(2): 179-197.
Elliott, D. (2002) Machine Translation Evaluation: Past, Present and Future. Unpublished MA dissertation, University of Leeds, UK.
Grishman, R. and M. Kosaka (1992) “Combining rationalist and empiricist approaches to machine translation”. In the Proceedings of the MTI-92, Montreal. Pp. 263-274.
Hutchins, W.J. (1986) Machine Translation: Past, Present, and Future. Chichester: Ellis Harwood.
Isabelle, P. and L. Bourbeau (1985) “TAUM-AVIATION: Its Technical Features and Some Expert mental results”. Computational Linguistics. 11(1): 18-27.
Isabelle, P., M. Dymetman, G. Foster, J.M. Jutras, E. Macklovitch, F. Perrault, X. Ren and M. Simard (1993) “Translation analysis and translation automation”. In the Proceedings of the TMI-93, Kyoto. Japan.
Kay, M. and M. Röscheisen (1993) “Text-translation alignment”. Computational Linguistics. 19(1): 13-27.
Kay, M. (1980) “The Proper Place of Men and Machines in Translation”. CSL-80-11, Xerox, PARC.
Landau, S.I. (2001) Dictionaries: The Art and Craft of Lexicography. Cambridge: Cambridge University Press.
Oakes, M. and T. McEnery (2000) “Bilingual text alignment - an overview”. In Botley, S.P., A.M. McEnery, and A. Wilson (Eds.) Multilingual Corpora in Teaching and Research. Pp. 1-37. Amsterdam-Atlanta, GA.: Rodopi.
Ravin, Y. and C. Leacock (Eds.) (2000) Ploysemy: Theoretical and Computational Approaches. New York: Oxford University Press Inc.
Simard, M., G. Foster, and P. Isabelle (1992) “Using cognates to align sentences in parallel corpora”. In the Proceedings of TMI-92. Canadian Workplace Automation Research Center. Montreal.
Simard, M., G. Foster, M-L. Hannan, E. Macklovitch, and P. Plamondon (2000) “Bilingual text alignment: where do we draw the line?” In Botley, S.P., A.M. McEnery, and A. Wilson (eds.) Multilingual Corpora in Teaching and Research. Pp. 38-64. Amsterdam-Atlanta, GA.: Rodopi.
Sinclair, J. (1991) Corpus, Concordance, Collocation. Oxford: Oxford University Press.
Somers, H. (1999) “Example-Based Machine Translation”. Machine Translation. 14(2): 113-157.
Su, K.Y. and J.S. Chang (1992) “Why corpus-based statistics-oriented machine translation”. In Proceedings of the MTI-92, Montreal. Pp. 249-262.
Tagore, R. (1995) Bangla Shabdatattva. Kolkata: Biswabharati Prakashani.
Teubert, W. (2002) “The role of parallel corpora in translation and multilingual lexicography”. In Altenberg, B. and S. Granger (Eds.) Lexis in Contrast: Corpus-based Approaches. Pp. 189-214. Amsterdam/ Philadelphia: John Benjamins.