1. INTRODUCTION
In the machine translation of Sanskrit sentences, the primary concern of translation is the morphological parsing of the words of Sanskrit. Since, the words are a combination of more than one basic word, they have to be subdivided, and the subdivided words need to be parsed. The morphological parsing gives us total information of the class to which the separated words belong. The morphological parser consists of a set of transducers that transform the given input to a set of acceptable and probable words, forming a Morphological Dictionary. They also give the parse for these words. The second part of the parser is a Vichcheda module, which splits the input to the basic words of Sanskrit. Finally, a comparator compares the words in the dictionary and the output from the Vichcheda module, and concludes if the word/words that have been generated are recognized. The parsing of Sanskrit words is necessary because the parsed input determines what phrases will replace the Sanskrit text when it is translated into any other language.
The present material consists of six sections titled 'Morphological Parsing', 'Sandhi Vichcheda in Sanskrit', 'Parsing of Sandhi Based Words', 'Concluding Remarks' and 'Appendix'. The first two sections provide a background for the understanding of the paper. The 'Morphological Parsing' section gives a general introduction to morphological parsing and illustrates it using examples. An idea of how sandhi is performed in Sanskrit is given in the next section called 'Sandhi Vichcheda in Sanskrit'. The section titled 'Parsing of Sandhi Based Words' forms the core of the present paper. It gives the architecture of the proposed idea of the parser and discusses each of its parts giving examples wherever felt necessary. The critical view of the present material is given in the 'Concluding Remarks' section. The advantages and the possible future enhancements has also considered in this section. The 'References' section lists the different books and materials referred to in the process of developing this material. The last section gives the devanagri equivalents of the roman scripts used in this paper to represent Sanskrit text.
2. MORPHOLOGICAL PARSING
The morphological parsing of words belonging to natural languages involves, providing a structure of the given input indicating the different morphemes that constitute the input and how they are related to each other. Morphemes are smaller meaning bearing units of words. These morphemes can be broadly classified into stems and affixes, which may be prefixes, suffixes, infixes or circumfixes. While prefixes are those morphemes, which may appear before a stem, and postfixes are those that are applied to the end of the stem, circumfixes are those morphemes that may be applied on both sides of the stem. The morphemes categorized under infixes are those that appear inside a stem.
Any morphological parser must consist of parts acting as a lexicon giving an exhaustive list of all the morphemes present in the language, the morphotactic rules specifying the position of one morpheme with respect to another and a set of orthographic rules which specifies how two given morphemes combine. The lexicon combined with the morphotactics may be modeled using a finite automaton. The finite automaton may be a transducer of some kind. Orthographic rules may be used at a stage when it is needed that the morphemes be combined together to give the surface word.
Example 1
In a word like 'books'- 'book' and '-s' are the two morphemes. When the word 'books' is parsed, the parsed output tells us that the word was formed because a noun called 'book' had been used in its plural sense, i.e. the output could be something like- (book, Noun, Plural). This information can later be used to translate the word 'books' to other languages.
3. SANDHI VICHCHEDA IN SANSKRIT
The inputs to the parser are words, which may further be a merger of more than one Sanskrit word. This kind of systematic blend of words is called sandhi. The Sanskrit word sandhi means 'to join together'. Sandhi is a coalescence of two letters coming in immediate contact with each other. When two words are adjacent to each other, the last letter of one word and the first letter of the next word come in immediate contact and may lead to a unification of the two words to form a larger word. This unification takes place according to the rules of sandhi. Practically, a word formed by sandhi rules may contain any number of smaller words.
Broadly, the sandhi types may be classified as Swarasandhi and Halsandhi. Swarasandhi deals with vowel combinations, while Halsandhi deals with combinations of consonants.
Example 2
a) a+I=E as in sva+IraH=svEraH ( One acting willfully)
b) a+A=A as in rAmeNAnIwaH=rAmeNa+AnIwaH (Brought by Rama)
4. PARSING OF SANDHI BASED WORDS
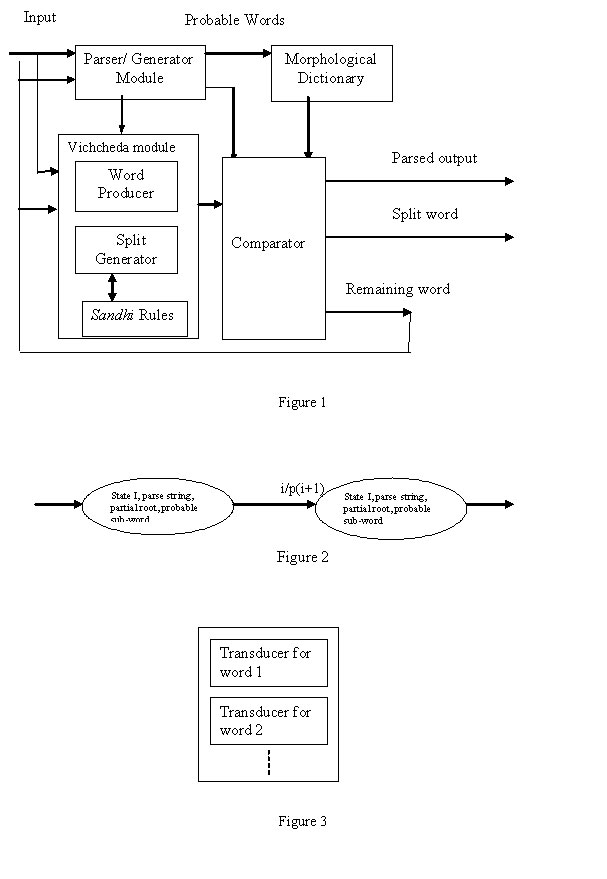
While parsing words formed using orthographic rules of sandhi, there is a need to generate all the set of sub-words contained in each input word along with the parsed output of each such sub-word. A model that helps us achieve this objective is given in the figure 1 below.
The Parser/Generator module uses a part of the input and generates the possible outcomes of a split that may be encountered. This information is stored in the morphological dictionary, which acts as a temporary buffer. Another string, which is also generated by the Parser/ Generator is used by the Vichcheda module. The Vichcheda module then converts this to an appropriate string, which confirms to the sandhi rules. It also appends a string to the beginning of the remaining string obtained after splitting. This module sends the modified strings to the Comparator. The Comparator matches the inputs it gets from the Morphological Dictionary with the first string obtained from the Vichcheda module. The next string is given back to the system as input. This process is repeated until the input word has been totally parsed.
The different blocks of figure 1 are described under:
Parser/Generator module:
This module is a collection of transducers as described before. The transducers are Moore Machines with multiple outputs. The transducers are defined as:
- A finite set of states s0, s1, s2� where s0 is the initial state.
- An alphabet A= ({devanagri letters} U null), for input strings and two sets of output strings.
- An output Alphabet O C (P {part of speech, case, number, gender, tenses, �} U null).
- An output table which gives the three sets of outputs.
- A pictorial representation that represents the transitions between states. A general representation is as shown in figure 2 below.
All transducers are combined to form a morphological parsing system module called the Parser/Generator. The design of this set of transducers is given in figure 3 where each transducer is of the type of figure 2. There is one transducer for each word, which takes care of its declination if applicable. The declination part is handled by adding the appropriate suffixes (obtained from the knowledge of the Sanskrit declination tables) to the stem. This job is taken care by the transducer. The input to the module is directed to the transducers. The transducers parse the input letter by letter. When enough input letters have been read that indicates some possible grammar characteristic, it is indicated in the 'parse string' output. At each state, an output corresponding to the string, i.e. 'partial root' is stored in the output table. This is sent to the Vichcheda module. Also, a 'probable sub-word' string is generated by various transducers and stored in the Morphological Dictionary.
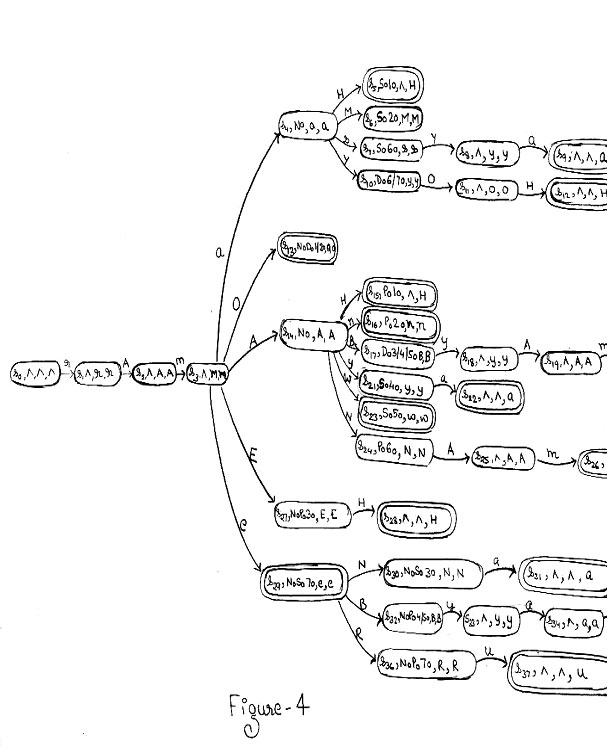
Example 3
The Sanskrit word rAmasyAcAryah (Acharya of Rama) is a coalescence of the words 'rAmasya' (of gods) and 'Acharyah' (Acharya or teacher). The transducer will parse 'rAmasya' first and then parse 'Acharyah' in the next turn. The transducer for 'rAma' is given as an example in figure 4.
Vichcheda Module
This module consists of three parts viz. the Word Producer, the Split Generator and the Sandhi Rule. The module takes the 'partial root' and the immediately following input letter/letters as input. If there are no such input letter/letters then the Word producer module simply transfers the 'partial root' to the Comparator, else, the Split Generator generates possible split outputs corresponding to the input letter/letters read. It determines the split outputs to be generated according to the Rules of Sandhi found in the Sandhi Rule unit of the Vichcheda module. The Word Producer concatenates the 'partial root' with all the first parts of the pair of outputs generated by the Split Generator module. It sends these concatenated words along with the second parts of the pair of outputs to the Comparator. Some rules of the Sandhi Rule module are given below:
A-> a,a | a,A | A,a |A,A
I-> i,i | i,I | I,i | I,I
U-> u,u | u,U | U,u | U,U
e-> a,i | A,i | a,I | A,I | e,a | a,e
E-> a,e | A,e | a,E | A,E
o-> a,u | A,u | a,U | A,U | o,a | a,o
O-> a,o | A,o | a,O | A,O
r-> a,q | A,q |
y-> i,(vowel) | I,(vowel) v-> u,(vowel) | U,(vowel) ay-> e,(vowel) av-> o,(vowel) Ay-> E,(vowel) Av-> O,(vowel) Where, (vowel)={a,A,i,I,u,U,e,E,o,O}
Morphological Dictionary
The set of 'probable sub-words' generated by Parser /Generator are temporarily stored in the Morphological Dictionary. The dictionary is volatile in the sense that it is cleared after every successful generation of a sub-word of the input. These words currently present are compared in the Comparator. In a smaller domain the Morphological Dictionary contains very few words or just one word. But as the domain of words increases, the Morphological Dictionary may be of great help in tracking the right word.
Comparator
Four inputs viz. the two strings from the Word Producer, the input from the Morphological Dictionary and the correct parse of each such input reach the Comparator. This module compares the list of words present in the dictionary with the first output string of the pair of outputs from the Word Producer. If the Comparator finds an exact match for the string in the dictionary, it sends this string along with its corresponding parse, as output. It also sends the second string input it received from the Word Producer back as input to the whole morphological parser system. If the second string is not present and the first string has been verified to exist then the Comparator indicates that the input has been recognized. At any stage if the Comparator is not able to find a match it indicates that the input is not recognized.
6. CONCLUDING REMARKS
In the machine translation of Sanskrit words we need to perform sandhi vichcheda of the input that is given to us. Thus at the very first stage of morphological parsing, there is a need for us to consider the splitting of words. This way the paper presented helps in fulfilling one of the very basic needs of the Sanskrit translator. The system has been generalized to handle any number of possible sub-words for a particular input. The system described may be enhanced to take care of all possible types of Sandhi by elaborating the rules given for the Sandhi Rule. There are many issues to be considered for a parse system of this type. One of which may be to consider the possible ambiguity caused when the same word (example - 'rAmAByam' of figure 4) occurs at two different cases. The solution to this problem should involve being able to select one parse out of the options given, for each occurrence of the word. This may be implemented at later stages of the translation.
REFERENCES
1. "Speech and Language Processing- an introduction to Natural Language Processing" by Daniel Jurafsky and James Martin, reprint 2000.
2. "Natural Language Processing" by Aksar Bharati, Vineet Chaitanya, Rajeev Sangal.
3. "Introduction to Computer Theory" -second edition by Daniel I.A.Cohen
4. "A Higher Sanskrit Grammar" by M.R. Kale
5. "Sandhi Viveka" by A.Varadaraj.
S. Aparna
aparnasubramanian@rediffmail.com
M. Ingle
maya_ingle@rediffmail.com
LANGUAGE IMPAIRMENT IN AUTISM | ON TEACHING POETRY IN INDIAN CONTEXTS - Some Observations and Suggestions | APODDHAARAPADAARTHA - THE PRINCIPLE OF INTELLECTUAL ABSTRACTION | MORPHOLOGICAL PARSING OF 'SANDHI' BASED WORDS IN SANSKRIT TEXT | THE CHINESE LANGUAGES: A NEW LEXICOGRAPHICAL PERSPECTIVE FROM HONG KONG | ENDANGERED LANGUAGES - A UNIQUE PROJECT TO SAVE THEM, A Report from the School of Oriental and African Studies | HOME PAGE | CONTACT EDITOR