AN APPEAL FOR SUPPORT

- We seek your support to meet expenses relating to some new and essential software, formatting of articles and books, maintaining and running the journal through hosting, correrspondences, etc. You can use the PAYPAL link given above. Please click on the PAYPAL logo, and it will take you to the PAYPAL website. Please use the e-mail address thirumalai@mn.rr.com to make your contributions using PAYPAL.
Also please use the AMAZON link to buy your books. Even the smallest contribution will go a long way in supporting this journal. Thank you. Thirumalai, Editor.

BOOKS FOR YOU TO READ AND DOWNLOAD
- THE ROLE OF VISION IN LANGUAGE LEARNING
- in Children with Moderate to Severe Disabilities ...
Martha Low, Ph.D. - SANSKRIT TO ENGLISH TRANSLATOR ...
S. Aparna, M.Sc. - A LINGUISTIC STUDY OF ENGLISH LANGUAGE CURRICULUM AT THE SECONDARY LEVEL IN BANGLADESH - A COMMUNICATIVE APPROACH TO CURRICULUM DEVELOPMENT by
Kamrul Hasan, Ph.D. - COMMUNICATION VIA EYE AND FACE in Indian Contexts by
M. S. Thirumalai, Ph.D. - COMMUNICATION
VIA GESTURE: A STUDY OF INDIAN CONTEXTS by M. S. Thirumalai, Ph.D. - CIEFL Occasional
Papers in Linguistics,
Vol. 1 - Language, Thought
and Disorder - Some Classic Positions by
M. S. Thirumalai, Ph.D. - English in India:
Loyalty and Attitudes
by Annika Hohenthal - Language In Science
by M. S. Thirumalai, Ph.D. - Vocabulary Education
by B. Mallikarjun, Ph.D. - A CONTRASTIVE ANALYSIS OF HINDI
AND MALAYALAM
by V. Geethakumary, Ph.D. - LANGUAGE OF ADVERTISEMENTS
IN TAMIL
by Sandhya Nayak, Ph.D. - An Introduction to TESOL:
Methods of Teaching English
to Speakers of Other Languages
by M. S. Thirumalai, Ph.D. - Transformation of
Natural Language
into Indexing Language:
Kannada - A Case Study
by B. A. Sharada, Ph.D. - How to Learn
Another Language?
by M.S.Thirumalai, Ph.D. - Verbal Communication
with CP Children
by Shyamala Chengappa, Ph.D.
and M.S.Thirumalai, Ph.D. - Bringing Order
to Linguistic Diversity
- Language Planning in
the British Raj by
Ranjit Singh Rangila,
M. S. Thirumalai,
and B. Mallikarjun
REFERENCE MATERIAL
- UNIVERSAL DECLARATION OF LINGUISTIC RIGHTS
- Lord Macaulay and
His Minute on
Indian Education - In Defense of
Indian Vernaculars
Against
Lord Macaulay's Minute
By A Contemporary of
Lord Macaulay - Languages of India,
Census of India 1991 - The Constitution of India:
Provisions Relating to
Languages - The Official
Languages Act, 1963
(As Amended 1967) - Mother Tongues of India,
According to
1961 Census of India
BACK ISSUES
- FROM MARCH 2001
- FROM JANUARY 2002
- INDEX OF ARTICLES
FROM MARCH, 2001
- APRIL 2005 - INDEX OF AUTHORS
AND THEIR ARTICLES
FROM MARCH, 2001
- APRIL 2005
- E-mail your articles and book-length reports (preferably in Microsoft Word) to thirumalai@mn.rr.com.
- Contributors from South Asia may send their articles to
B. Mallikarjun,
Central Institute of Indian Languages,
Manasagangotri,
Mysore 570006, India or e-mail to mallikarjun@ciil.stpmy.soft.net - Your articles and booklength reports should be written following the MLA, LSA, or IJDL Stylesheet.
- The Editorial Board has the right to accept, reject, or suggest modifications to the articles submitted for publication, and to make suitable stylistic adjustments. High quality, academic integrity, ethics and morals are expected from the authors and discussants.
Copyright © 2004
M. S. Thirumalai
THE ROLE OF CONTEXT IN SENSE VARIATION -
INTRODUCING CORPUS LINGUISTICS IN INDIAN CONTEXTS
Niladri Sekhar Dash, Ph.D.
1. INTRODUCTION
All natural languages have a set of words, which vary in sense when used in a piece of text. Context plays an important and active (rarely passive) role to influence words to generate contextual senses, which often divert from the original sense derived either from etymology or morphology. It implies that context plays a pivotal role in partial or total modification of sense as well as projection of new senses. Therefore, by observing words in contexts we can decipher actual contextual senses.
In most cases, factors like knowledge of external world, discourse and pragmatics, interface underlying linguistic communications, registers, social relationships existing among participants, and socio-cultural background of speech acts, etc. empower us to obtain actual sense of words from contexts. But to design a sophisticated tool for word sense disambiguation in language technology, we need a thorough analysis of context to understand the phenomenon in minute details.
It is agreed that various fields of linguistics and language technology benefit from the analysis of lexical ambiguity. Although, the task of comprehensive sense analysis and interpretation is highly complex in nature, there has been significant progress in theories, description, and processing.
The present discussion focuses on this area to establish a knowledge-based interpretation of lexical meaning, and emphasise on the extraction of information from corpus to represent, manipulate, and interpret meaning of words.
2. SENSE DISAMBIGUATION
To deal with the problem of sense disambiguation of words, two major approaches are proposed so far. While knowledge-based approach aims at using information obtained from explicit sets of lexicon (Schütze 1998, Coleman and Kay 2000, Cuyckens and Zawada 2001), corpus-based approach proposes to use information of word meaning retrieved from corpus (Ravin and Leacock 2000, Vera 2002).
We prefer to work with the corpus-based approach where the possible way to attribute senses to words is triggered by ‘context’. Contextual word refers to the words, which are found to be used with the target word (TW)1 in a particular context in a piece of text. Thus, contextual word refers to the collocational information of words.
We intend to extract necessary information from the analysis of contexts processed methodically to understand actual contextual sense. To substantiate our argument, we draw supporting evidence from the Bangla (Bengali) corpus of written texts (Dash and Chaudhuri 2000).
3. PROPOSITIONS ABOUT WORD MEANING
With regard to word meaning, the proposition of traditional lexical semantics is strongly criticized by modern linguists, who argue that meaning of words actually comes from the context of their usage. Malinowsky, one of the chief exponents of the proposition, opines that:
'... the meaning of any single word is to a very high degree dependent on its context ... a word without linguistic context is a mere figment and stands for nothing by itself, so in reality of a spoken living tongue, the utterance has no meaning except in the context of situation' (Malinowsky 1923: 307).
Almost similar arguments are put forward by Firth (1957: 21) to claim that actual sense of words is known from the company they keep. Gaustad (2001: 24) also observes that 'the only way to determine the meaning of a word in particular usage is to examine its context'. Similar propositions are made by Lyons (1963: 80) and Cruse (2000: 51) who advocated that sense variation of words would be realized from their contexts, which ask for elaborate introspective analysis for understanding word sense. Nida (1997: 265) also emphasizes the context (both cultural and linguistic) for the same purpose.
The central idea is that the senses of a word detached from its contextual frame are incomplete. We require contextual information of various types for proper analysis and understanding of actual sense of words.
4. INDIAN GRAMMARIANS
Centuries ago, Indian grammarians also appreciated the value of context in understanding the actual sense of words. To them, words are meaningful only when they are put together to form a sentence. They argued that while literal senses are extendable and changeable according to the context of their use, actual senses are derivable from the contexts of their use (Verma and Krishnaswamy 1989: 330). This implies that senses of words are associated with syntactic, topical, prosodic, idiomatic, and similar characteristically observable contexts (Mindt 1991: 185).
These arguments direct us toward a theory of context-based sense of words bound with various observable distributional environments. However, the decipherment of actual contextual sense is not a trivial task since, in some cases, it is hidden within non-linguistic expression of users to be understood by numerous extra-linguistic devices.
5. THE ISSUE OF SENSE VARIATION
Once we agree with the argument that words are related with several senses, the question of sense variation becomes an important issue in lexical semantics. It implies that words have multiple senses triggered by way of semantic extension. For example, kOthA in Bangla (Bengali) refers to word, statement, description, narration, story, event, opinion, promise, excuse, context, order, suggestion, provocation, prescription, conversation, compulsion, request, explanation, and similar senses. It reveals a network of intricate relation among the senses, which hardly come to surface for easy dissolution. It also refers to the following features that provide clues for designing systems for sense disambiguation.
· A word has a (explicit or implicit) core sense.
· This core sense can change due to contextual variation of word.
· The newly formed sense has a relation with the core sense.
6. HOW DOES SENSE VARY?
How does sense vary due to variation of context? This is a standing question not only in lexical semantics but also in lexicography, lexicology, language education, and word sense disambiguation. Context itself has the answer hidden into it. Therefore, we must initiate search to know what kind of information it supplies and how does it supply.
7. THE CORPUS
In general, a corpus helps us to locate contexts methodically, classify them according to their features, and access them for necessary information. Availability of electronic corpus makes these tasks easier, which are not possible via intuitive evidence (Gale et al. 1992).
Corpus, enriched with all possible empirical evidences of word use, adds a new dimension to linguistics never attempted in generative school. Thus, corpus linguistics excels over intuitive linguistics not only in the work of supplying a wider spectrum of contexts of word use, but also in providing necessary contextual information for understanding the variation of sense a word can possibly denote. However, evidence acquired from corpus shows that only linguistic factors (i.e. structure, usage, part-of-speech, synonymy, lexical collocation, lexical gap, etc.) do not control sense variations. There are some extra-linguistic factors (i.e. figurative, idiomatic, and metaphoric use; pragmatics and discourse; features of dialogic interaction; various socio-cultural settings, types of register, etc.), which often contribute, to a large extent, to the variations of word sense.
8. CONTEXT IN SENSE VARIATION – A MYSTERIOUS PROCESS OF SELECTION
Interestingly, a word, when put in a particular context, denotes only one sense out of multiple senses it carries. It is still an enigma how it happens. The general assumption is that it is the context that actually determines which sense is to be considered. If this is true, then there is a debate regarding the issue of determining a context, since there is no well-defined process to identify it automatically. It is argued that identification of context depends mostly on the intuitive ability of language users. This does not solve the problem. Rather, it leads us to give up the problem with the conviction that persons endowed with richer intuition will excel over others.
At present, however, corpus is found to be useful, since words have multifaceted representations with sufficient contextual ambience in it. Before we explore how corpus contributes in context search, let us first understand what context means and what its properties are.
9. 1. WHAT IS A CONTEXT?
Linguistically, ‘context’ refers to an environment in which an item occurs. It can be a phoneme, morpheme, word, phrase, clause, sentence, or a similar form. For the present discussion, the context of word is considered here. Not necessarily, context is explicit always. It may be hidden within neighbouring zone or located at distant places linked to the text or topic under investigation. That means, we cannot extract all relevant information of words from their immediate contexts only. We have to take the topic of discussion under consideration, since relevant information may hide here.
Taking these factors into account, Miller and Leacock (2000) divide context into two types: Local Context (LC) and Topical Context (TC). LC constitutes one/two words before and after the TW in a sentence, while TC refers to the topic of the text.
In our argument, these are not enough to capture all necessary and required information for understanding intended senses of a word. At certain readings, information acquired from these contexts is sufficient, but they cannot be the ultimate sources for all possible readings.
Therefore, to acquire more information, we propose to classify context into four broad types: Local Context (LC), Sentential Context (SC), Topical Context (TC) and Global Context (GC). The conceptual hierarchical layering of the contexts is presented in the diagram (Fig. 1).
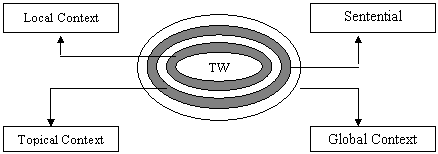 |
Fig. 1: Conceptual hierarchical layering of the contexts
In the above diagram (Fig. 1), LC provides the basic information about the sense variation of words. Therefore, it is accessed to obtain information from neighbouring words of the TW. If it fails, SC is analysed to retrieve information from sentence where the TW is used. Next, TC is explored to acquire further information from the content of topic under discussion. Finally, GC is accessed to acquire information from extralinguistic world. The process of systematic extraction of information from contexts is presented in the following diagram (Fig. 2), which displays the role of contexts in generation of new senses of words.
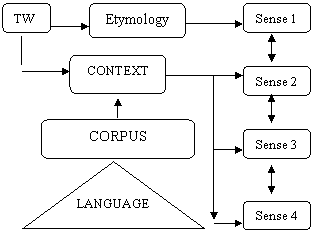
Fig. 2: Generation of new sense due to variation of context
In the following section, each context is analysed to show where does it belong, how does it act to create variations in sense, and how information obtained from it helps us to understand the actual contextual sense of words.
9. 2 LOCAL CONTEXT
LC refers to the immediate environment of TW in a sentence encompassing both preceding and succeeding words. Conceptually, W1, TW, and W2 constitute a lexical block (LB) where TW is the main member while W1 and W2 are supporting members. Systematic interpretation of LB supplies information to retrieve actual contextual meaning of TW. Moreover, members of LB generate a network of ‘mutual functional relation’ from which the intended sense of TW is derivable by integrating senses provided by the neighbouring members. In majority of cases, due importance to LC helps us to obtain actual sense. Within the model of Saussaurean structuralism, this is a unique network of functionally related elements within which each separate element derives its essence from its functional relation with other elements used in a text (Verschueren 1981: 326)2.
To examine how LC supplies information to understand contextual sense of TW, Kaplan (1955) initiated an interesting study. On experimental basis, he designed four sets of LBs where he put TW in the middle and one word in each side (±1) at a time in the following way (Fig. 3). The data set was distributed to a large number of native speakers to examine if they could understand the actual sense of TW by exploring functional relations of the associated words. Each informant was provided with only one set at a time in a sequential order: Set_1 followed by Set_2, Set_3, and Set_4, etc.
|
Set_1 : |
|
LW1 |
TW |
RW1 |
|
|
Set_2 : |
|
LW1 |
TW |
RW1 |
RW2 |
|
Set_3 : |
LW2 |
LW1 |
TW |
RW1 |
|
|
Set_4 : |
LW2 |
LW1 |
TW |
RW1 |
RW2 |
Fig. 3: Position of TW in LC
(RW = Right Word, TW = Target Word, LW = Left Word)
From analysis of results it is found that a native speaker can understand the actual contextual sense of TW if s/he is provided with a LB of 5 words (i.e. Set_4) where the TW occurs in the middle. Informants do not need to know the whole sentence. After a few years, Chouka and Lusignan (1985) initiated another innovative experiment the result of which substantiated Kaplan’s observation. Both the studies claimed that information embedded within LC is enough for understanding actual contextual sense of words.
However, the results evoked mixed reactions among scholars. Those who work in the area of machine translation (MT) and word sense disambiguation (WSD) expected that if meaning of words is possible to extract from LC, then many unwanted problems of MT and WSD will be dissolved without further difficulty. On the other hand, those who did not agree with the results raised various counter arguments to highlight the limitations of the experiments. In their argument, information obtained from LC is not enough, since we need more information from other fields to understand actual contextual sense. Nevertheless, we find that LC, with reference to the members included in LB, provides varieties of contextual information in the following way.
First, LC provides necessary information to know if TW holds any idiomatic relation with its neighbouring members. For instance,
(1) tAr ‘khAoyA-pOrAr’ khOrOc khub beshi nOy |
His ‘eating–wearing’ expense much more (is) not
“The cost of his ‘living’ is not very high.”
In the above example, occurrence khAoyA and pOrA as two neighbouring members within LC leads us to consider them together an idiomatic expression with a special sense (SS), which cannot be derived if they occur separately at two distant places. Without further reference to any other context, we can understand that khAoyA is not used in the sense of ‘eating’. Its latent relation with pOrA denotes ‘living’. However, to draw finer distinctions among idiomatic senses, we need to use ‘semantic meta-language’ (Goddard 2000), which provides clues for discriminating the senses. Also, a machine-readable dictionary (MRD), which is made with processed text, dictionarial definition of word, information of lexical selectional restriction, pragmatic and discoursal knowledge, etc. is required for the work.
Second, LC is useful for understanding collocational relation between the words used in LB. From here, we can know if occurrence of two words is caused by choice (to evoke an intended sense) or by chance (having no special significance). It is noted that association of two words (i.e. W1 and W2) may denote a special sense (SS) (idiomatic or metaphoric), which cannot be obtained from the totality of their individual literal sense (LS). That means, collocation of W1 and W2 in LC may generate SS1, which differs from LS1. Interestingly, collocation of W2 with W3 will generate SS2, which is different from LS2. For example, let us consider the following examples (Table 1) collected from Bangla corpus.
Neighbouring Words |
Literal Sense |
Special Sense |
|
AdA nun khAoyA |
eating ginger and salt |
work with determination |
|
kOlA khAoyA |
eating banana |
fail in a mission |
|
kocupoRA khAoyA |
eating roasted arum |
eating rubbish |
|
ghOnTA khAoyA |
eating bells |
eating nothing |
|
mAthA khAoyA |
eating head |
spoil one’s character |
|
cAkri khAoyA |
eating one’s service |
rusticate one from job |
|
tel khAoyA |
eating oil |
pleased with flattery |
|
hAoyA khAoya |
eating air |
eating nothing |
|
DigbAji khAoyA |
eating a vault |
act conversely |
|
nun khAoyA |
eating salt |
get help from someone |
Table 1: Variation of sense due to lexical collocation
Third, Even when there is no idiomatic relation, LC informs if TW holds any sense variation due to its relation with a neighbouring word. Consider the following examples, where in each case, information extracted from ±1 of TW is handy to find out its actual sense without further reference to other contexts. Here, extra-linguistic information obtained from the preceding word helps to retrieve actual sense of TW.
(2a) tArA bhAtW1 ‘khAy’TW
They rice eat
‘They eat rice’.
(2b) tArA dudhW2 ‘khAy’TW
They milk drink
‘They drink milk’.
(2c) tarA sigAreTW3 ‘khAy’TW
They cigarette smoke
‘They smoke cigarette’.
By using extra-linguistic knowledge (i.e. practical and pragmatic senses) we know that bhAt is a solid item which we eat, dudh is a liquid item which we drink, while sigAreT is a solid (?) item which we some. This knowledge helps us to understand that khAy means ‘eating’ in (2a), ‘drinking’ in (2b), and ‘smoking’ in (2c). Thus, khAy, the TW, is used in three different senses linked with a core sense represented in following diagram (Fig. 4).
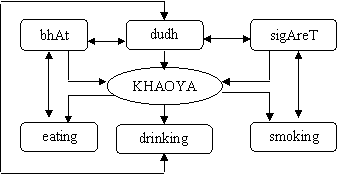 |
Fig. 4: Variation of word sense due to lexical gap
It should be realised that this has been possible due to lexical gap where the lack of a suitable lexical item expressing a particular sense is compensated by expansion of sense of another conceptually similar lexical item available in a language. However, LC is not the only source for providing all kinds of information necessary for sense disambiguation. We have to rely on the information available from other contexts as described below.
9. 3 SENTENTIAL CONTEXT
SC refers to that particular sentence where the TW is present. It supplies all types of syntactic information to know if TW has any explicit/implicit syntactic interface with other words used in sentence. Evidence acquired from corpus shows that a set of two words, although used at distant places, maintains a special kind of relationship. It mostly happens in case of group verbs and phrasal units where two constituents, despite their phrasal unity, are separated from each other to be located at distant places (e.g. He went to station to see his brother off, etc.) In such cases, SC allows to explore if there is any variation of sense of TW due to its relation with other members located far away. Here, the most complex task is the identification of that ‘other member’ with whom TW maintains a special kind of relation. For example,
(3a) baRabAbur ‘nuN’ sArA jIbOne Onek ‘kheyecha’, ebAr ekTu gun gAo.
Barabau-gen salt whole life much have eaten, now little praise
‘You have been indebted enough to the Barababu. Now praise him a little.’
In sentence (3a), although nuN and kheyecha (TW) form an idiom with a figurative sense, they are situated far away from each other. A few words are inserted between them. To understand actual sense of TW (i.e. kheyecha) we do not depend on the words placed immediately before and after it. We need to retreat to nuN. That means, meaning of nuN has is associated with that of TW to evoke a figurative sense. A MRD made with idioms, group verbs, and phrases helps here to match and identify which two words, in spite of distant location, carry special sense relation. We also use extralinguistic knowledge and native language efficiency to understand the actual sense of TW in such disjoined constructions.
9. 4 TOPICAL CONTEXT
TC refers to the topic of discussion as well as content of a piece of text. Quite often, actual sense of TW depends on content, which traditional linguistics identifies as ‘subject matter’. Here also, meaning of TW changes due to the impact of content of discourse referred to in the text. For example, shot depending on content of discourse changes its sense to denote various items and ideas. Based on variation of discourse, in war it means ‘to fire a gun’, in ale house ‘to drink alcohol’, in cricket ‘to hit the ball with a bat’, in football ‘to kick a ball’, in basket ball ‘to put a ball in net’, in golf ‘distance between player and hole’, in photography ‘take a snap’, in medicine ‘to give an injection’, in sex language ‘to have sex’, etc.
The examples show that sense variation of words takes place due to variation of discourse - a regular phenomenon in natural language. It also implies that we extract relevant information from the content of discourse to trail the changes of sense of TW. To elucidate the role of TC in trailing down sense variations, let us analyse the examples given below.
(4a) khAli peTe ‘khAben’ nA.
empty stomach-gen. eat-will not
‘Do not take in empty stomach.’
(4b) ‘khAoyAr’ Age kichu ‘kheye’ nin.
eat-gen before something eat (do) take
‘Eat something before you take it’.
(4c) ‘khAoyAr’ Age er sOnge kichuTA jOl mishiye ‘khAn’,
eat-gen before this with some water mix eat-imp.
‘Mix some water with it before you take it’.
(4d) khub bhAla hOy yadi bOrOph mishiye ‘khete’ pAren.
very good (is) if ice mixing could eat
‘It would be nice if you mix it with some ice’.
If each of the above sentences (4a-4d) is analysed as a single, separate, and independent sentence, it will be found that the verb khAoyA does not have any notable sense variation. But if sentences are knit together and analysed accordingly, a fine shade of sense variation is noted among the forms (i.e. khAben, khAoyAr, kheye, khAn, and khete) of the verb. Taken together, the lemma KHAOYA, at different contextual environment, displays a special sense, which is obtained neither from its lexical class, nor from its suffix property, nor even from its LC. The special sense is possible to decipher only when the content of discourse is referred to and interpreted accordingly.
The first reading of first three sentences (4a-4c) apparently refers to an instruction about the way of taking medicine, which is quite common in doctor’s prescription. However, a quick reference to bOrOph ‘ice’ in the last sentence (4d) immediately turns the whole attention from medical prescription to the guideline for drinking liquor. Usually, leaflets provided to consumers contain such lines where ways of preparation and consumption are meticulously stated to obtain maximum satisfaction. Diversion of sense takes place because mixing ice with medicine is a rarer event in comparison to mixing ice with liquor. Thus, reference to the content of discourse becomes instrumental for obtaining necessary information to decipher actual contextual sense of TW.
9. 4 GLOBAL CONTEXT
Words are not isolated linguistic entities. They are related not only to other words, but also to the extra-linguistic reality (Verschueren 1981: 337). So do the senses of words. Senses of TW are not only related to the senses of other words occurring within LC, SC, and TC, but also to the extra-linguistic reality. Verbs, in general, evoke a scene of action constituting an agent and an item, which are co-ordinated with particular place, time, and discourse (Fillmore 1977: 82). Let us consider the following sentence.
(5) O to ekTA baipokA, sArAdin bai ‘kheye’ kATAy |
He indeed (is) a bookworm, whole day book eating passes.
‘He is indeed a bookworm, (s/he) devours books the whole day’.
For understanding actual sense of kheye in sentence (5), information from GC is essential, since information available from other contexts is not sufficient for understanding the actual sense of TW. Here, TW is used in the sense of ‘always reading books’, which is decipherable only when both literal and metaphoric senses of ‘baipokA’ is understood. In literal sense, a bookworm is ‘a larva of a moth or beetle which feeds on the paper and glue used in books’ (Illustrated Oxford Dictionary, 1988), but in its metaphoric sense, it is ‘a person devoted to reading’. Once it is conceived that a human being is referred to as a ‘bookworm’, it is understandable that TW is used not in simple literal sense but in a metaphoric sense. Thus, understanding of contextual sense of words depends on general use of language, metaphoric use of words, and pragmatic knowledge of users.
Generally, a large part of information of GC is derived from the external world from where we gather discoursal information of texts, register information of language use, and demographic information of language users. Conceptually, GC that fabricates a relation between words and external world, includes information obtained from world and time, co-texts3, situation and interpretation, pragmatics and discourse, demography, geography, society, culture, ethnology, and other sources (Allan 2001: 20). It builds up a cognitive interface between language and reality, by which we conceive: who says, what is said, to whom it is said, when it is said, where it is said, why it is said, and how it is said. Thus, GC becomes the most important and valuable source for sense disambiguation of words because it supplies necessary information to know if TW has any sense variation, and if so, what is that sense.
10. INTERFACE AMONG THE CONTEXTS
The discussion presented above implies that we understand sense variations of words by using information from various contexts. This, however, creates an impression that contexts are characteristically different, that they have no link of interdependency, and that they have no conceptual interface among themselves. It also gives an impression that we have to proceed in a sequential order to reach to the final context.
This is not true, since each context is inter-linked with the other by an invisible thread of interdependency. Therefore, we use information of one context while dealing with the other. Even, if required, we use information from all contexts together to dissolve the problem at hand. As there is no proposition for sequential use of contextual information, we start with any context and slide to the other as the problem demands. If we need information from GC while dealing with LC, we can do that. To understand how the interface works, let us consider the example given below.
(6) Ap(a)nAr rabibArer chATniTA pAblik dArun ‘kheyeche’ |
your Sunday-gen chatni-the public very much has eaten.
‘Your Sunday article is well accepted by the readers’.
To understand the actual sense kheyeche, we have to use information from all the contexts, since the TW is used in a very discrete manner with a highly figurative (metaphor) sense. To know the actual sense of TW, we must have answer to the following questions: who has made the statement? To whom the statement is made? When it is said? Where it is said? What does the word chATni mean? What does the phrase robibArer chATni refer to? How does robibArer chATni become palatable to public? Furthermore, thoughtful reading of the word-pair ‘chATni … kheyeche’ shows that it is used not in a simple literal sense, but in a sarcastic figurative sense. Here, information collected from all sources helps us to derive the inner meaning of the construction, conceive the interface inherent in the network of time-place-agent-action, and capture the actual contextual sense.
In our argument, LC carries primary importance in understanding sense variation of words. We access SC, TC, and GC for additional information only when LC fails to provide it. Thus, reference to other contexts comes in subsequent stages, when information obtained from LC is found insufficient. SC, which refers to sentence where TW occurs, includes immediate environment of TW focusing on both of its neighbouring members as well as distant members. On the other hand, TC refers to topic of a text where TW has occurred. At conceptual level, it tries to fabricate a sense relation between TW and the topic of a text. Finally, GC refers to the extra-linguistic source from where we gather all kinds of information related with the external world.
Generally, the degree of understanding of sense variation depends on the width and depth of world knowledge of language users. People equipped with wider range of linguistic as well as extra-linguistic knowledge and experiences are more compatible for understanding contextual sense than others. A native Bangla user, for example, who has wider experience about Bengali life, language, and society, can easily grab the sense of kheyeche (6) than those who have learned Bangla as their second language and have limited exposure to Bengali life, language, and society.
11. CORPUS IN SENSE DISAMBIGUATION
A corpus is considered as a reliable resource for identifying the range of senses as well as extracting actual contextual sense, since it makes significant contribution towards empirical analysis of contexts with close reference to usage. Standard dictionaries usually fail here, because the range of sense variation that shows up in corpus far exceeds the number of sense distinctions provided in dictionary (Fillmore and Atkins 2000, Kilgarriff 2001). Present availability of corpus simplifies the process of accessing context of words, because with little programming skill, we can easily retrieve all possible use of words from corpus without much difficulty. After compiling the examples from corpus, we analyse the data to understand the range of sense variation, pattern of sense change, nature of semantic gradience, factors behind sense variation, and many such factors. In essence, corpus saves us from referring to our intuition for obtaining possible senses of words. It provides much more information, which is available neither from linguistic knowledge nor from native language intuition.
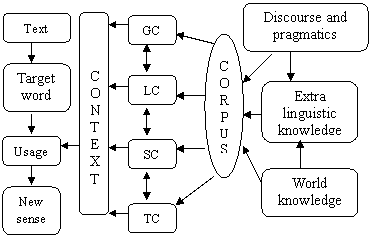 |
Fig. 5: Accessing corpus to know contextual sense of words
Variation of sense comes from various sources of words: internal morphemic structure, etymological history, dictionarial entity, lexical class, grammatical function, synonym and antonym, contextual occurrence, lexical association, lexical collocation, area of usage, content of discourse, and similar other controlling factors4. Corpus is capable to refer to all possible contexts required for understanding sense variation, since it provides both linguistic (e.g. morphological, lexical, grammatical, semantic, syntactic, etc.) and extra-linguistic (e.g. telic, deictic, temporal, tense, spatial and event information related to pragmatics and discourse) information - essential ingredients for identifying sense variation, observing total range of senses, differentiating related senses, and extracting actual contextual sense. Once relevant information is obtained and analysed, all possible sense variations are captured. The above diagram (Fig. 5) shows how corpus is to be used to know contextual sense of words.
In a language, we come across a large set of words, which have sense variation. Therefore, our first task is to find out if a word is attributed with the quality of sense variation. To dissolve this, we use information from two sources: dictionary and corpus. Dictionary supplies information if a word has sense variation (i.e. multiple sub-entry in meaning will determine polysemous entity of a word) while corpus will provide information about the range of sense variation. Total range is possible to identify if a corpus contains large representative sample of all text types with wider genre and subject variation. Now, once a polysemous word is found, we want to know:
· How many sense variations does the word possess?
· In which (contextual) sense it is used in a particular context?
To find answers to these questions, we refer to both context-free as well as context-bound information. While context-free information is available from etymology, part-of-speech, grammatical properties, dictionary, thesaurus, and similar referential sources, context-bound information is obtained from LC, SC, TC, and GC. It is not likely that information obtained from all these sources is used always whenever we try to understand sense variation, but it helps us to understand sense variation as well as obtain actual contextual sense from the score of multiple senses. A method (AIMS = Access of Information from Multiple Sources) for extracting both types of information is proposed below (Fig. 6) where, following a systematic step-by-step process of ‘input-analysis-output’ scheme, we obtain information from both the intra-linguistic and extra-linguistic contexts to understand sense variation as well as to extract actual sense of words.
First we use information from various sub-fields of words in their context-free situation. For instance, information obtained from suffix or case ending used with a word plays decisive role in disambiguation. This becomes useful because many inflected words in a language like Bangla are sidelined to a particular part-of-speech and sense after using class-specific suffix or case ending. For example, khete can either be a noun or a verb in context-free situation: it is noun if a nominal case ending is tagged to it (e.g. khet + -e[Case_Loc] ® khete[NN]) or it is verb if a verbal suffix is tagged to it (e.g. khe- + -te[Sfx_NFV] ® khete[NFV]). Thus, identification of suffix marker or case ending often helps to categorise a word to a particular lexical class and sense without further reference to its context of use. In the same process, depending on the need, we refer to etymological, lexical, dictionarial and thesaural information of words to understand their sense variation in context-free situation. But, if we find that information obtained form the sub-fields related to context-free situation is not sufficient for understanding sense variation, we refer to context-bound information embedded within corpus as well as information stored in extra-linguistic sources.
 |
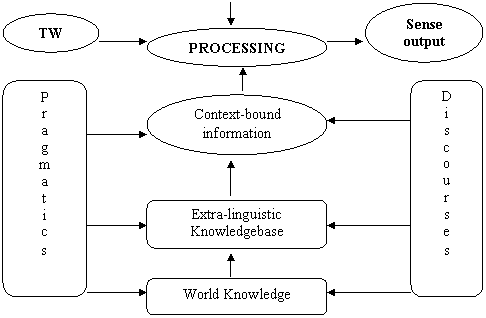 |
Fig. 6: The AIMS method for sense disambiguation of words
In sum, in the AIMS method we propose to use all kinds of information. We use lexical information stored in dictionary, morphophonemic information found in grammar, contextual information embedded in corpus, figurative information stored in MRD, and extra-linguistic information hidden in real world. It is robust and efficient in sense understanding, since it applies linguistic information acquired from referential sources and non-linguistic information obtained from corpus, discourse, and the world at large.
12. CONCLUSION
A word, in essence, is a bundle of information related to phonology, morphology, morphophonemics, lexicology, semantics, syntax, morpho-syntax, text, grammar, etymology, metaphor, discourse, pragmatics, world knowledge, and others (Pinker 1995: 344). It is not easy to capture all the information just by looking at its surface form or orthography. We require a versatile system along with native language intuition to decipher all possible explicit and implicit senses of words used in a piece of text.
Theoretically, we support Moravcsik (2001) to argue that it is not necessary to define all possible and potential variations of sense of words. If we do, we damage severely the productivity and flexibility of language, and burden both lexicon and language learners excessively. Sense variation is a vital attribute of a natural language. It leaves things in a state of incompleteness out of which productive devices generate new literal and metaphoric alternatives to cope with novel experience.
However, in lexical semantics, computational linguistics, natural language processing, automatic word sense disambiguation, machine translation, and other fields of language technology, we are troubled with the problem of sense variation. Therefore, we need to understand the phenomenon for applying it in various fields of language technology (sense discrimination, information retrieval, content analysis, WordNet design, natural language understanding, text alignments, parsing, etc). Also, we need systematic information of sense variation of words for dictionary making, linguistic theory building, and language teaching. Besides, systematic study of sense variation of words helps us to establish more firmly the notion of semantic indeterminacy and semantic gradience in the area of language cognition.
NOTES
[1] A Target Word (TW) is the word, which is put to investigation for exploring the nature of its ambiguity and sense variation evoked from its polysemous entity.
[2] With respect to the vocabulary of a language, it implies that meaning of words depends on the existence of other words, which opposes attempts for defining meaning of words independently. Meaning of each word covers a relatively small ‘semantic area’, which is a part of a wider ‘conceptual area’, generated after the convergence of some ‘semantic areas' of words. Within this frame, the size of a semantic area is determined by the size of the semantic areas of surrounding words.
[3] Co-text is a text that usually precedes and succeeds a given language expression to cover total linguistic information embedded in it. For details, see Allan (2001: 20-21).
[4] For details, see Ide and Véronis (1998), and Kilgarriff and Palmer (2000).
REFERENCES
Allan, K. (2001) Natural Language Semantics. Oxford: Blackwell Publishers.
Chouka, Y. and S. Lusignan (1985) “Disambiguation by short context”. Computer and the Humanities. 19: 147-157.
Coleman, J. and C.J. Kay (Eds.) (2000) Lexicology, Semantics, and Lexicography. Amsterdam-Philadelphia: John Benjamins.
Cruse, A. (2000) Meaning in Language: An Introduction to Semantics and Pragmatics. Oxford: Oxford University Press.
Cuyckens, H. and B. Zawada (Eds.) (2001) Polysemy in Cognitive Linguistics. Amsterdam/ Philadelphia: John Benjamins.
Dash, N.S. and B.B. Chaudhuri (2000) “The process of designing a multidisciplinary monolingual sample corpus”. International Journal of Corpus Linguistics. 5(2): 179-197.
Fillmore, C.J. (1977) “Topics in lexical semantics”. In Cole, R. W. (Ed.) Current Issues in Linguistic Theory. Pp. 76-138. Bloomington: Indiana University Press.
Fillmore, C.J. and B.T.S. Atkins (2000) “Describing polysemy: the case of ‘crawl’”. In Ravin, Y. and C. Leacock (Eds.) Ploysemy: Theoretical and Computational Approaches. Pp. 91-110. New York: Oxford University Press Inc.
Firth, J.R. (1957) “Modes of meaning”. In Papers in Linguistics 1934-1951. London: Oxford University Press.
Gale, W., K.W. Church, and D. Yarowsky (1992) “A method for disambiguating word senses in a large corpus”. Computers and the Humanities. 26(4): 415-439.
Goddard, C. (2000) “Polysemy: a problem of definition”. In Ravin, Y. and C. Leacock (Eds.) Ploysemy: Theoretical and Computational Approaches. Pp. 129-151. New York: Oxford University Press Inc.
Goustad, T. (2001) “Statistical corpus-based word sense disambiguation: pseudo-words vs. real ambiguous words”. Companion Volume to the Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics (ACL-2001). Pp. 24-29.
Ide, N. and J. Véronis (Eds.) (1998) Computational Linguistics. Special Issue on Word Sense Disambiguation. Vol. 24. No. 1, 1998.
Kaplan, A. (1955) “An experimental study of ambiguity and context”. Mechanical Translation. 2: 39-46.
Kilgariff, A. and J. Palmer (Eds.) (2000) Computer and the Humanities: Special Issue on Word Sense Disambiguation. Vol. 34. No.1, 2000.
Kilgarriff, A. (2001) “Generative lexicon meets corpus data: the case of nonstandard word uses”. In Bouillon, P. and F. Busa (Eds.) The Language of Word Meaning. PP. 312-328. Cambridge: Cambridge University Press.
Lyons, J. (1963) Structural Semantics. Cambridge: Cambridge University Press.
Malinowsky, B. (1923) “The problem of meaning in primitive languages”. In Supplement to C.K. Ogden and I. A. Richards (1923) The Meaning of Meaning. (9th Edition 1946). Pp. 52-65. London: Keegan and Paul.
Miller, G. A. and C. Leacock (2000) “Lexical representations for sentence processing”. In Ravin, Y. and C. Leacock (Eds.) Ploysemy: Theoretical and Computational Approaches. 151-160. New York: Oxford University Press Inc.
Mindt, D. (1991) “Syntactic evidence for semantic distinctions in English”. In Aijmer, K. and B. Altenberg (Eds.) English Corpus Linguistics. Studies in Honour of Jan Svartvik. Pp. 182-196. London: Longman.
Moravcsik, J. M. (2001) “Metaphor; creative understanding and the generative lexicon”. In Bouillon, P. and F. Busa (Eds.) The Language of Word Meaning. Pp. 247-261. Cambridge: Cambridge University Press.
Nida, E.A. (1997) “The Molecular Level of Lexical Semantics”. International Journal of Lexicography. 10(4): 265-274.
Pinker, S. (1995) The Language Instinct: The New Science of Language and Mind. England: Penguin Books.
Ravin, Y. and C. Leacock (Eds.) (2000) Ploysemy: Theoretical and Computational Approaches. New York: Oxford University Press Inc.
Schütze, H. (1998) “Automatic Word Sense Disambiguation”. Computational Linguistics. 24(1): 97-123.
Vera, D.E.J. (2002) A Changing World of Words: Studies in English Historical Lexicography, Lexicology and Semantics. Amsterdam: Rodopi.
Verma S. K. and N. Krishnaswamy (1989) Modern Linguistics: An Introduction. Delhi: Oxford University Press.
Verschueren, J. (1981) “Problems of lexical semantics”. Lingua. 53: 317- 351.
CLICK HERE FOR PRINTER-FRIENDLY VERSION.
A MALAYSIAN ENGLISH TEXTBOOK FOR MALAYSIAN LEARNERS OF ENGLISH | THE ROLE OF CONTEXT IN SENSE VARIATION - INTRODUCING CORPUS LINGUISTICS IN INDIAN CONTEXTS | TEACHING LITERARY TRANSLATION PRACTICALLY | AN AGITATION IN SUPPORT OF MEITEI SCRIPT | A NEW BOOK SERIES OF CLASSICAL SANSKRIT LITERATURE | WORD CLASSES OR PARTS OF SPEECH IN TAMIL | SINDH IN THE SUPREME COURT | THE ROLE OF COMMUNICATION IN EFFECTIVE INSTRUCTIONAL DELIVERY |THE BIRTH OF KUMAARA, A NEW TRANSLATION OF KUMARA SAMBHAVAOF KALIDASA | HOME PAGE | CONTACT EDITOR
Niladri Sekhar Dash, Ph.D.
Computer Vision and Pattern Recognition Unit
Indian Statistical Institute
203, B.T. Road
Kolkata 700108, India
ns_dash@yahoo.com
Send your articles
as an attachment
to your e-mail to
thirumalai@mn.rr.com.